Gesuperviseerde classificatie
Intro
Achtergrond
Gesuperviseerde classificatie is een classificatiemethode die gebruik maakt van een door de gebruiker samengestelde trainingsdataset die representatief is voor de gewenste klassen. Het classificatie-algoritme gebruikt deze trainingsdata als referentie om onbekende pixels in het beeld te classificeren.
Een essentieel onderdeel hierbij is voorkennis van het gebied. De verzamelde trainingssamples, ook wel bekend als ground truth data, weerspiegelen de feitelijke landbedekking op specifieke locaties.
Er zijn verschillende methoden om ground truth data te verzamelen:
-
Veldbezoek: Ter plaatse worden GPS-data verzameld. Deze methode levert de meest kwalitatieve en betrouwbare data, maar is arbeidsintensief en kostbaar.
-
Gebruik van referentiekaarten of hogeresolutiebeelden: Hiervoor kunnen bestaande kaarten of recent beeldmateriaal, zoals drone-opnames, worden gebruikt.
-
Handmatige interpretatie van satellietbeelden: Hierbij wordt de gebruiker ondersteund door expertkennis en ervaring om de beelden correct te interpreteren.
Belangrijk is dat de trainingsdata zo dicht mogelijk in de tijd liggen bij het remote sensing-beeld dat geclassificeerd wordt, aangezien landbedekking snel kan veranderen door factoren zoals stadsontwikkeling, ontbossing, seizoensgebonden invloeden, agrarische veranderingen en kusterosie.
In deze oefening rond gesuperviseerde classificatie zul je zelf trainingssamples moeten aanmaken. Hiervoor heb je een beknopt verslag van een veldcampagne ter beschikking, dat inzicht biedt in de aanwezige landbedekkingsklassen. Aangezien we ons beperken tot enkele klassen, kun je je trainingsdata aanmaken op basis van een satellietbeeld/sentinel-2 beeld. Het aanmaken en analyseren van verschillende beeldcomposieten kan hierbij nuttig zijn.
Beeldcomposieten aanmaken
- Start opnieuw met het aanmaken van een wolkenvrije dataset, dewelke kan overgenomen worden van vorige oefening. Belangrijk hier is ook om de gewenste banden te selecteren, die we tijdens de classificatie gaan aanmaken.
// --------------------------------------------------------------------
// STAP 1 - Inladen en klaarzetten van S2-beeld. Mét extra cloud-masking
// -------------------------------------------------------------------
// Studiegebied:
var ROI = ee.Geometry.Polygon(
[[[-55.31615692285674, 5.999656479357525],
[-55.31615692285674, 5.8043169248564865],
[-55.02364593652862, 5.8043169248564865],
[-55.02364593652862, 5.999656479357525]]], null, false)
//Cloudprobability functie:
// Functie die nieuwe CloudProbability collectie samenvoegt met S2 (sen2cloudless)
// meer info: https://medium.com/sentinel-hub/cloud-masks-at-your-service-6e5b2cb2ce8a
var getS2_SR_CLOUD_PROBABILITY = function () {
var innerJoined = ee.Join.inner().apply({
primary: ee.ImageCollection("COPERNICUS/S2_SR_HARMONIZED"),
secondary: ee.ImageCollection("COPERNICUS/S2_CLOUD_PROBABILITY"),
condition: ee.Filter.equals({
leftField: 'system:index',
rightField: 'system:index'
})
});
var mergeImageBands = function (joinResult) {
return ee.Image(joinResult.get('primary'))
.addBands(joinResult.get('secondary'));
};
var newCollection = innerJoined.map(mergeImageBands);
return ee.ImageCollection(newCollection);
};
// Mask out clouds
var maskClouds = function(image) {
var cloudProbabilityThreshold = 40;
var cloudMask = image.select('probability').lt(cloudProbabilityThreshold);
return image.updateMask(cloudMask).divide(10000).copyProperties(image);
};
//Aanmaken van een ImageCollection ter hoogte van Mangroves Paramaribo, Suriname
var S2_coll = getS2_SR_CLOUD_PROBABILITY()
.filterDate('2024-08-01','2024-10-30')// Filteren voor het jaar 2024, droge tijd
.filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE',50)) //Voorselectie obv wolken
.map(maskClouds) //toepassen van de cloudmaskfunctie
.filterBounds(ROI); //collectie filteren obv de Kustzonegeometrie
//print('Sentinel-2_collectie, S2_coll)
//Omzetten collectie naar een Image, door .median() te nemen. Hierna clippen we ook tot onze ROI
//Ook selecteren we de banden waarmee we verder willen werken
var bands = ['B2','B3','B4','B5','B6','B7','B8','B8A','B11','B12'];
var S2_im = S2_coll.median()
.select(bands)
.clip(ROI) //Bekijk de .clip-eigenschappen in de Docs
Map.centerObject(S2_im, 11)
Map.addLayer(S2_im,{min:0.05,max:0.1800,bands:'B4,B3,B2'},'NormaleKleuren_2024',0)
Map.addLayer(S2_im,{min:0.0700,max:0.4500,bands:'B8,B4,B3'},'ValseKleuren_2024',0)
Map.addLayer(S2_im,{min:0.0500,max:0.4000,bands:'B8,B11,B2'},'Healthy_Vegetation_2024',0)
Trainingsamples aanmaken
"Whereas the actual classification of multispectral image data is a highly automated process, assembling the training data needed for classification is anything but automatic. In many ways, the training effort required in supervised classification is both an art and a science" Lillesand & Kiefer (pg 544)
-
Nadat het wolkenvrije Sentinel-2 beeld is ingeladen, kunnen we deze gebruiken om enkele representatieve samples te verzamelen van enkele landbedekkingklassen waar we in geïnteresseerd zijn. Er zijn 2 manieren om trainingsdata in Earth Engine op te laden:
-
Door ze in te tekenen als polygonen binnen per klasse, zoals we in komend voorbeeld zullen toepassen.
-
Door eerder ingetekende trainingssamples of GPS-punten op te laden als een 'Asset'. Dit kunnen shapefiles, of .csv-bestanden zijn.
-
-
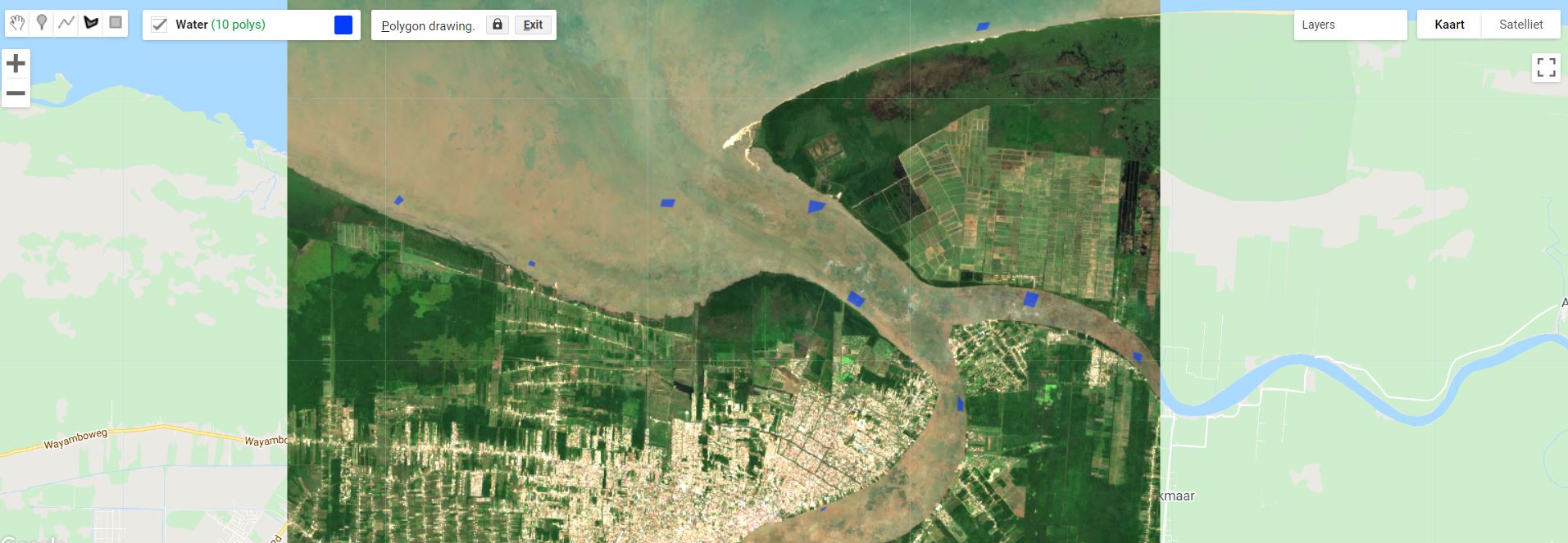
Hover met je muis over de 'Geometry Imports box, dat zich naast de geometrietools bevindt. Klik op *'+new layer'.
-
Elke gewenste landbedekkingsklasse dient als een afzonderlijke laag te worden aangemaakt. Laat ons bijvoorbeeld starten met de eenvoudigste klasse 'water'. Zoom in op het beeld en teken polygonen in over oppervlaktes waar je zeker van bent dat het waterlichamen betreft. Het is goed hierin te variëren binnen verschillende types van zowel zee als rivieren en andere waterlichamen. Teken ca. 10 polygonen in per klasse. Neem hiervoor zeker je tijd, gezien het belangrijk is dit zeer precies te doen. De kwaliteit van de inputdata bepaalt tevens de kwaliteit van de classificatie, oftewel Garbage in = Garbage out. Als je een fout gemaakt heb, kun je even op 'exit' duwen en de laats ingetekende polygoon verwijderen.
| class | Landbekkingsklasse |
|---|---|
| 1 | Mangrove |
| 2 | OtherForest |
| 3 | Water |
| 4 | Crop |
| 5 | Urban |
| 6 | BareSoil |
Polygonen vs puntdata als traingdata
Trainingdata kan bestaan uit puntdata of trainingdata. Beiden hebben hun voor- en nadeel.
Puntdata gebruiken als inputdata kan bijvoorbeeld als je beschikt over een grote set GPS-veldpunten van locaties waar je exact weet tot welke landbedekkingsklasse een pixel hoort. Deze pixel wordt dan als referentie aanschouwt. Deze zekerheid van de trainingsdata is dus groot. Een nadeel bij pixels is dat het minder de variëteit van de pixels binnen de klasse opneemt en de totale set aan trainingspixels beperkt blijft.
Polygonen worden gebruikt om gebieden in te tekenen voor een bepaalde klasse. In earth engine wordt elke pixel binnen deze polygoon dan gebruikt als inputdata. Dit zorgt ervoor dat de trainingsset groter wordt en de variatie binnen een bepaalde klasse beter wordt omvat. Een nadeel is echter dat zo ook foute pixels kunnen worden meegenomen door het onzorgvuldig intekenen van de polygoon.
- Eenmaal je klaar bent met het intekenen van een klasse, kun je deze import configureren. Klik hiervoor op het tandwieltje naast de klasse. Geef het een gepaste naam. Daarna verander je de 'Import as' van geometry naar type FeatureCollection. Voeg daarna een property toe met de naam 'class', door te klikken op 'Add property'. De eerste klasse geef je waarde 1, de 2e 2, .... Zorg er wel voor dat je goed weet welke waarde je aan welke klasse geeft. Neem hierbij eventueel de class-numering over van bovenstaande tabel.
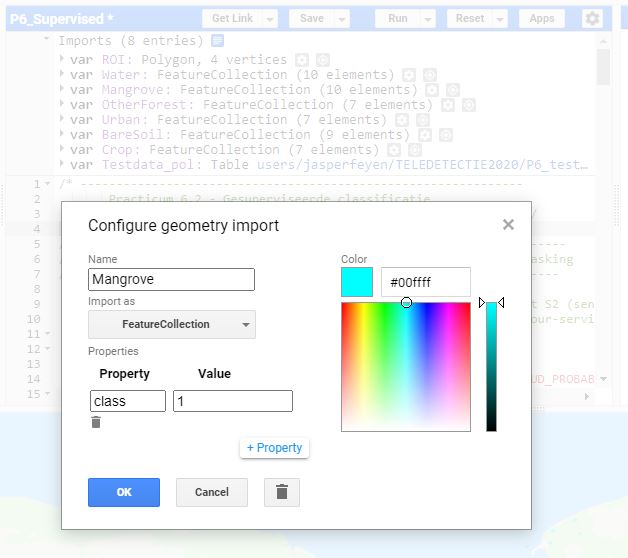
- Herhaal dit voor elke klasse. Uiteindelijk verschijnt elke klasse als een 'FeatureCollection' bij de imports-lijst in je script:

Voorbeeld trainingsamples voor Mangrove
- Nu de 5 klassen aangemaakt zijn, dienen we ze samen te vatten als een complete trainingsset in earth engine; een gezamenlijke
FeatureCollection, waarbij de 'class'-property wordt overgenomen.
//2. Trainingssamples samenvoegen tot 1 ```FeatureCollection```
var classNames = Mangrove.merge(OtherForest).merge(Water).merge(Crop).merge(Urban).merge(BareSoil);
print(classNames)

De trainingsdata aanmaken
Nu hebben we reeds een FeatureCollectionmet trainingspolygonen, maar deze zeggen nog niks over de trainingspixels. In een volgende stap, extraheren we de trainingspixels per band uit het Sentinel-2 beeld op basis van de aangemaakte polygonen. Dit doen we met de sampleRegions()functie. Deze functie extraheert alle pixels binnen opgegeven polygonen, en schrijft elke pixel afzonderlijk naar een nieuw `Featurebinnen een FeatureCollection, dewelke ook de class-property meekrijgen. Afhankelijk van de grootte van de polygonen, kan deze dataset dus zeer lijvig worden.
//Trainingspixels extraheren naar featurecollection = trainingsdata
var traindata = S2_im.sampleRegions({
collection: classNames, //De trainingspolygonen
properties: ['class'], //Dit neemt de gewenste eigenschappen van de collection over
scale: 10,
tileScale:4
});
print('Aantal trainingspixels: ',traindata.size());
//print(traindata) //Niet doen
print(traindata.first()) //Eerste waarde bekijken,
Layer error: Computed value is too Large
Mogelijks heb je bij het gebruik van sampleRegions() al onderstaande foutmelding gehad:

tileScale aand de sampleRegions()-functie, zoals in bovenstaand voorbeeld werd gedaan. Door het verhogen van de tileScale zal Earth Engine de opdracht in meerdere stukjes indelen, waardoor de berekening minder gemakkelijk 'out of memory' zal lopen. De bewerking zal hierdoor wel meer tijd in beslag nemen, dus verhoog tileScale slechts gelijdelijk.
Zie ook de 'Docs' van sampleRegions()
De classifier trainen
In een volgende stap maken we een classificatiemodel aan en trainen we deze op basis van de traindata. Er bestaan verschillende mogelijke classifiers en 'machine learning'-algoritmen. In Google Earth Engine zitten deze beschikbaar in de ee.Classifier-groep. We gebruiken er 3, waarna we kijken dewelke tot de meest accurate classificatie leidt o.b.v. de validatiedata.
Minimum Distance Classifier
In een eerste instantie dienen we de classifier te trainen, op basis van de opgestelde trainingsdata. We dienen ook aan te geven welke van de properties binnen de trainingssamples de 'class'-bevat, en welke properties gebruikt moeten worden om mee te classificeren (de banden).
//4. De classifiers trainen en toepassen
// A. Minimum Distance classifier (gebruik van default-waarde 'euclidische afstand')
var MinDist = ee.Classifier.minimumDistance().train({
features: traindata,
classProperty: 'class',
inputProperties: bands //verwijzing naar de eerder aangemaakte bands-lijst
});
CART classifier
// B. CART classifier
var Cart = ee.Classifier.smileCart().train({
features: traindata,
classProperty: 'class',
inputProperties: bands //verwijzing naar de eerder aangemaakte bands-lijst
});
Random Forest classifier
// C. Random Forest
var RandomForest = ee.Classifier.smileRandomForest({
numberOfTrees: 60
}).train({
features: traindata,
classProperty: 'class',
inputProperties: bands //verwijzing naar de eerder aangemaakte bands-lijst
});
Beeld classificeren en visualiseren
Eenmaal de classifier(s) opgesteld zijn, kunnen ze worden toegepast op het volledige S2-beeld. Elke pixel wordt dus toegekend tot een klasse, op basis van de kennis opgedaan uit de trainingsdata.
// 5. Classifiers toepassen
//MinimumDistance
var classified_MD = S2_im.classify(MinDist)
var classified_CART = S2_im.classify(Cart)
var classified_RF = S2_im.classify(RandomForest)
Bij het visualiseren willen we een visueel overzichtelijk resultaat krijgen. Aangezien we eindigen met discrete klassen, stellen we hiervoor een palette op, dat per klasse een kleur aangeeft.
var palette = [
'FF0000', // mangrove (1) // rood
'7CFC00', // ander bos (2) // lichtgroen
'1E90FF', //water (3) // blauw
'FFFD10', //crop (4) //geel
'000000', //stad // zwart
'876829', //BareSoil // bruin
];
var classvis = {min:1, max:6, palette: palette}
Map.addLayer(classified_MD,classvis,'MinimumDistance')
Map.addLayer(classified_CART,classvis,'CART')
Map.addLayer(classified_RF,classvis,'RandomForest')