Accuracy assessment
Accuraatheidsbepaling (Accuracy assessment)
In de accuraatheidsbepaling evalueren we de effectiviteit van het classificatiemodel door te kijken naar de foutmarge. Deze beoordeling is gebaseerd op een foutenmatrix. Voor het opstellen hiervan hebben we een set van onafhankelijke testgegevens nodig. Kortom, we willen begrijpen hoe goed de classifier onbekende pixels classificeert.
Training- Validation en Testdata
Een veel gebruikte methode bij het opstellen van modellen, is het opsplitsen van de trainingset-dataset in training- en validatiedata. Hierbij wordt de trainingdata at random gesplits in meestal een 80/20-verhouding. Daarnaast wordt er vak nog gebruik gemaakt van een derde, volledig afzonderlijke dataset: de testdataset:
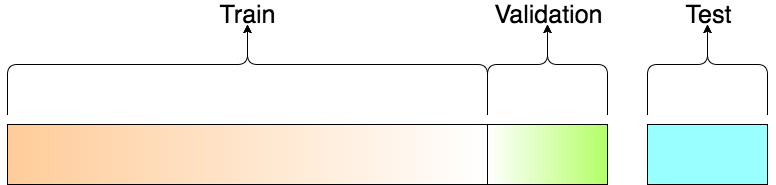
Traindata= de data gebruikt om het model te trainen en dus te fitten. Het model bekijkt en leert van deze data.
Validatiedata= Het deel van de data dat gebruikt zal worden om na te gaan hoe goed het model werkt op onbekende data. Dit deel zal dus niet gebruikt worden om het model te trainen. Hierdoor kunnen verschillende classificatiemodellen en parameters binnen het model tegenover elkaar worden afgewogen en het model zo worden geperfectioneerd. Dit wordt ook wel parameter tuning genoemd. Validatiedata wordt dus gebruikt tijdens de ontwikkeling en het zoeken van het beste model. Bij spatiale data echter, dient hier voorzichtig mee te worden omgegaan door het fenomeen van spatiale autocorrelatie. Hierbij zijn de validatiepixels veelal buurpixels van de trainpixels. Dit is het geval wanneer er bijvoorbeeld gebruik gemaakt wordt van polygonen als inputdata.
Testdata = Deze afzonderlijke dataset wordt gebruikt om bij een finaal model accuraatheidsmaten van de bekomen classificatie te berekenen. Testdatasets worden meestal ook zeer goed verzorgd en zijn goed verzamelde (veld)datapunten. De spatiale autocorrelatie vervalt hier.
De Error Matrix: interpretatie
Zie ook de foutenmatrix handboek pagina 577
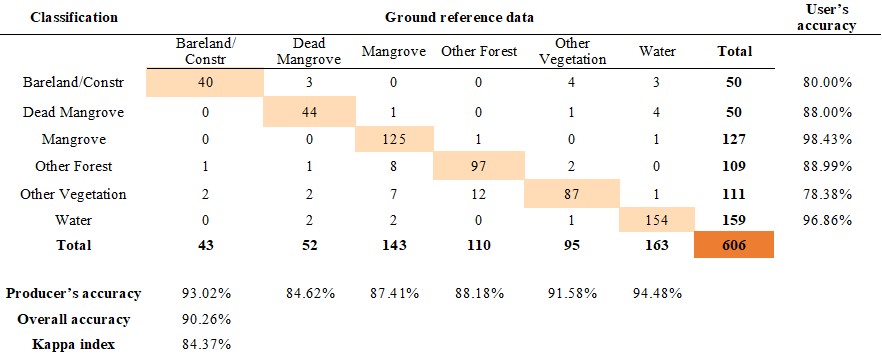
De foutenmatrix (of Error Matrix) wordt opgesteld waarin de werkelijke klassen van de geclassificeerde pixels worden vergeleken met de voorspelde klassen. Deze matrix biedt inzicht in verschillende soorten fouten, zoals fout-positieven, fout-negatieven en correcte classificaties. Onderstaande matrix geeft een voorbeeld van dergelijke matrix:
- Rijen: resulaat van de classificatie
- Kolommen: validatie data
- Diagonaal: pixels die goed geclassificeerd zijn (validatie data = classificatie)
-
Niet-diagonaal:
-
Omissie: de niet diagonale kolom-elementen. Deze pixels behoren tot een klasse, maar werden ingedeeld in een verkeerde klasse. In het voorbeeld: 18 pixels moesten Mangrove zijn, maar werden ingedeeld onder andere klassen: 1 als 'Dead Mangrove', 8 als Other Forest, 7 als Other Vegetation en 2 als *Water.
-
Commissie: Deze pixels geven aan welke pixels verkeerd werden ingedeeld in deze klasse. Voor Water zijn dit er bijvoorbeeld 2 (moesten 'Dead Mangrove') + 2 (moest Mangrove zijn + 1 (moest Other Vegetation zijn) = 5 pixels verkeerdelijk als 'Water' ingedeeld.
-
Op basis van de error matrix kunnen er accuraatheidsmaten worden berekend.
-
Overall accuracy: Dit is de som van de diagonale elementen, gedeeld door het totaal aantal pixels (= "juist ingedeeld"/totaal).
-
Producer accuracy (of Recall): het aantal correct ingedeeld pixels in elke klasse, gedeeld door het aantal validatiepixels van die klassen. Het geeft een indicatie hoe goed de validatiepixels geclassificeerd werden (Bijvoorbeeld Mangrove = (125/143 = 87,41% werd goed geclassificeerd)). Deze maat geeft de probabiliteit weer dat een pixel die in een bepaalde klasse werd gestopt in werkelijkheid ook tot die klasse behoort.
-
User/consumer accurcay (of Precision): Het aantal correct geclassificeerde pixels in elke klasse (diagonaalelementen), gedeeld door het aantal pixels ingedeeld in die klasse (rijtotaal).
-
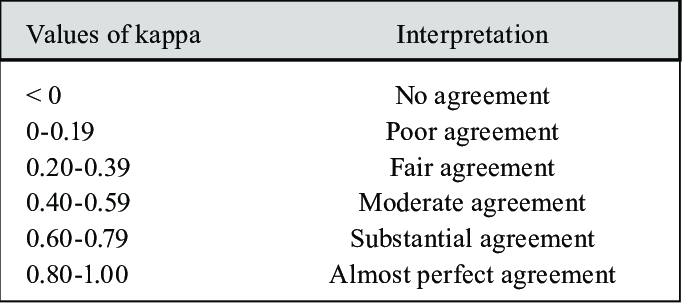
Kappa index: de kappa index is een gecorrigeerde accuraatheidsmaat, die intra- en interobserver agreement in rekening houdt. Het houdt m.a.w. rekening met pixels die per toeval juist geclassificeerd zijn. Onderstaande tabel geeft een interpretatie weer van de kappa-waarde.
De Error matrix in Earth Engine
Toevoegen van de testdataset
In voorliggend voorbeeld maken we gebruik van een extra testdataset voor het opstellen van de error matrix. Gezien we geen optimalisatie van parameters gaan doorvoeren, maken we geen gebruik van validatiedata en wordt de volledige trainingscollectie ook trainingsdata.
De gebruikte testdataset bestaat uit kleine polygonen met een diameter van 25m en representeren GPS-punten genomen op veldbezoek. De 25m-buffer rond de GPS-punten werd genomen om voldoende testpixels te weerhouden voor de accuracy assessment.
Je kunt de shape-file hier downloaden: P4_testdata_poly.zip
Om deze toe te voegen aan Earth Engine, laad je deze op via de 'Asset'-tab. Daarna kun je het importeren als een FeatureCollection in je script. Noem dit 'Testdata_pol'. Bekijk ook even deze polygonen. Onder welke property zitten de klassen hier opgeslagen?
Vervolgens extraheren we de pixelwaarden op basis van deze testpolygonen, net zoals we dit gedaan hebben bij de trainingspixels:
//Na inlezen van validatiedata: maak een testdatacollectie, zoals bij het opmaken van traindata
print('Testpolygonen',Testdata_pol) //bekijk de properties
//Testpixels extraheren naar featurecollection
var testdata = S2_im.sampleRegions({
collection: Testdata_pol, //De trainingspolygonen
properties: ['val'], //Dit neemt de gewenste eigenschappen van de collection over
scale: 10
});
print('Aantal testpixels: ',traindata.size());
Nu we de testpixelwaarden geëxtraheerd hebben, kunnen we deze vergelijken met de geclassificeerde pixels in een error matrix. Tevens staat Earth Engine een rechtstreekse berekening van de verschillende accuraatheidsmaten toe. In onderstaand stukje code staat het voorbeeld voor de Minimum Distance classifier. Pas dit toe voor alle classifiers. Welke classifier heeft de grootste algemene accuraatheid (Overall accuracy)?
// Validatie met de testdata
var val_MinDist = testdata.classify(MinDist);
var ErrorMatrix_MinDist = val_MinDist.errorMatrix('val', 'classification')
print('MinDist Validation error matrix: ', ErrorMatrix_MinDist.array().transpose());
print('MinDist Validation overall accuracy: ', ErrorMatrix_MinDist.accuracy());
print('MinDist Producer Accuracy: ', ErrorMatrix_MinDist.producersAccuracy());
print('MinDist User/Consumer Accuracy: ', ErrorMatrix_MinDist.consumersAccuracy());
print('Kappa index: ', ErrorMatrix_MinDist.kappa());
//Omzetten naar een Feature + transpose
var ErrorMatrix_MinDist = ee.Feature(null, {matrix: ErrorMatrix_MinDist.array().transpose()});
De Error matrix in Earth Engine
In Earth Engine wordt de error matrix opgeroepen met de ee.ConfusionMatrix()-functie. Resulterend is een lijst met 7 elementen (de rijen), waarbij elke rij op zijn beurt bestaat uit 7 elementen (de kolommen). In Earth Engine corresponderen de rijen met de referentiedata en de kolommen met de geclassificeerde data. Met de array.().transpose() functie kunnen we deze matrix transponeren, zodat deze overeenkomst met de matrix in het voorbeeld (kolommen: referentie, rijen: geclassificeerd), wat de standaard weergave is.

Voorbeeld: interpretatie error matrix
In ons voorbeeldje werd onderstaande ErrorMatrix verkregen voor de MinDist classifier. Door de .transpose()-functie komt de referentiedata terecht in de kolommen, terwijl de classificatiedata zich in de rijen bevindt.
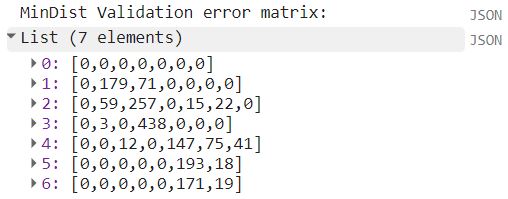
Na wat opschoning in excel, ziet de error matrix van dit voorbeeld er uit als volgt:
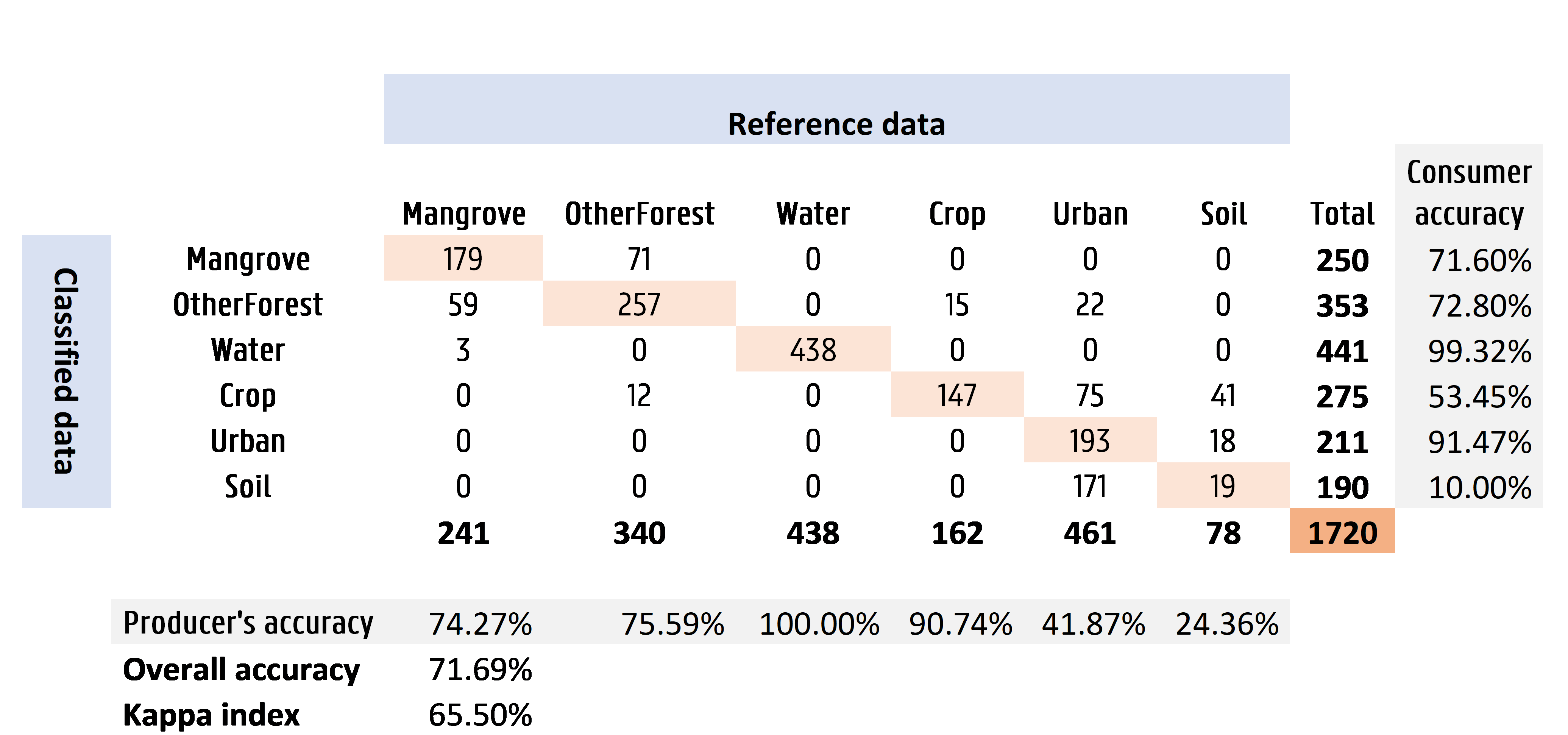
Welke klassen scoren goed? Welke zijn minder accuraat? Aan de overall accurcay en de Kappa index kan worden afgeleid dat de classificatie reeds een goede indicatie heeft, maar nog voor verbetering vatbaar is. Hoofdzakelijk de klassen 'water' en 'crop' scoren goed, terwijl 'Soil' moeilijker te onderscheiden valt van 'crop' en 'urban'. Betere trainingsdata is hier dus de boodschap!
Extra: Exporteren van de Error Matrix
In Google Earth Engine is de weergave van de error matrix niet zo handig. Om verdere accuraatheidsmaten uit te rekenen en een betere interpretatie te kunnen uitvoeren kan het handig zijn om de error matrix te exporteren als een .csv-bestand, dewelke in andere software (zoals excel) geopend kan worden.
Met de Export.table.toDrive()-functie kunnen we de matrix exporteren naar onze Google Drive. Hiervoor dienen we dit eerst om te zetten naar een feature.
//Omzetten naar een Feature
var ErrorMatrix_MinDist = ee.Feature(null, {matrix: ErrorMatrix_MinDist.array()});
//Exporteren van de errormatrix
Export.table.toDrive({
collection: ee.FeatureCollection(ErrorMatrix_MinDist),
description: 'P4_Errormatrix',
fileFormat: 'CSV',
folder: 'TELEDETECTIE_2024'
});
Volledig script
Via deze link: https://code.earthengine.google.com/460852f85607a70e818bc45df5da2d73?accept_repo=users%2Fhansakwast%2FCB4WAGEE