These are examples to support our EURASIP special issue journal paper under peer review.
Reference:
@{Robustness of ad hoc microphone clustering using speaker embeddings: Evaluation under realistic and challenging scenarios}
Goal
We have ad-hoc distributed microphones and two concurrent speakers placed in a room. We want to
cluster the microphones in three clusters: one for each speaker and one background cluster.
We compare the Mod-MFCC based clustering features with
our proposed speaker embedding features. Both are clustered using fuzzy-C-means (FCM) clustering, with the euclidean and
cosine distance
With these clusters, we perform
speech separation by first generating a rough estimate via masking. This estimate is subsequently used to estimate the relative delays,
which are then compensated for during delay and sum beamforming (DSB). Further, we make use of the fuzzy values of the FCM clustering to perform a weighted delay and sum beamformer, called fuzzy value aware DSB (FMVA-DSB).
Lastly, we use the beamformed signal to compute a postfilter.
Setup
For the examples, we used different room sizes and reverberation times from the SINS simulated dataset.
2 sources are placed in the living area of the apartment. Then 16 microphones are randomly placed with the constraint that at least 3 microphones are within the critical distances of each source.
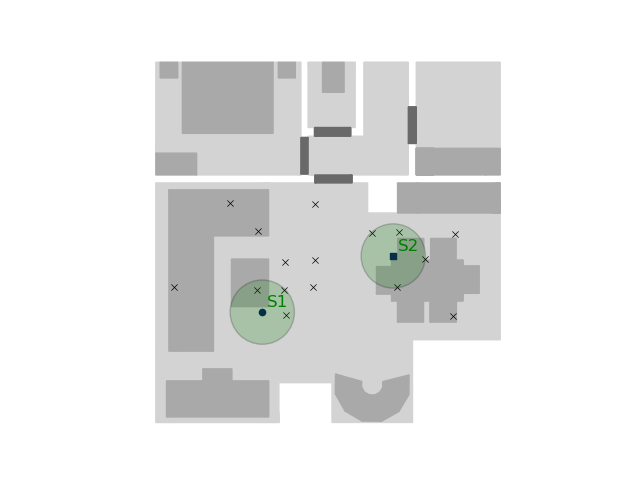
An example room and cluster is plotted below, where the sources are the green crosses, the critical distances is indicated by the black circle/square and the microphones are indicated with black dots.
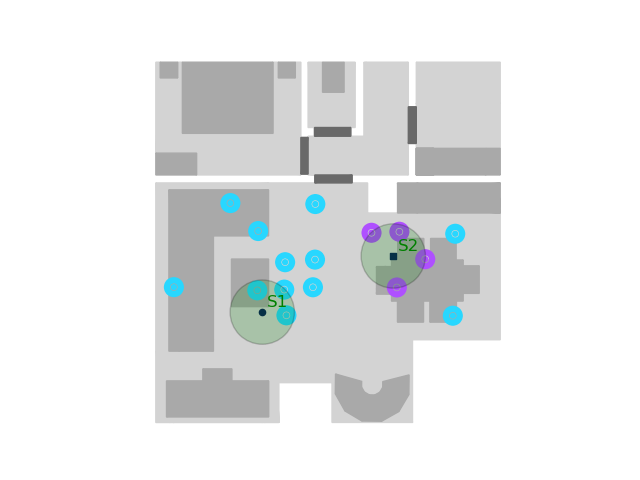
For the clustering,
microphones with darker purple color belong to the same cluster, while light blue dots are microphones not belonging to that cluster.
Note that the critical distances will change dependant on the room size and the revereration time of the room.
Evaluation
To compare between Mod-MFCC based features and the Speaker Embeddings, we will show the following:
- What the cluster are
- Audio of the chosen reference microphone signals
- Audio of the masked reference microphone signals, which will be used to time-align the signals
- Audio of the DSB output for the clusters
- Audio of the FMVA-DSB output for the clusters
- Audio of the postfiltered output for the clusters
Cases
We have 2 different examples where sources are closer or farther separated from each other.
- Sources that are farther separated
- Sources with overlapping critical distances
See also:
We previously have also performed clustering on
shoe-box like acoustics .